文本分类是自然语言处理领域的一项核心任务,旨在将文本数据自动分配到预定义的类别中。在人工智能基础软件开发的背景下,文本分类系统通过一系列关键技术实现高效准确的分类。以下是其基本原理和关键技术的详细说明。
一、文本分类的基本原理
文本分类基于监督学习或深度学习的思想,其核心流程包括:
- 数据预处理:对原始文本进行清洗、分词、去除停用词和标准化(如词干提取或词形还原),以消除噪声并统一格式。
- 特征提取:将文本转换为机器可理解的数值向量。传统方法使用词袋模型或TF-IDF(词频-逆文档频率),而现代方法则采用词嵌入(如Word2Vec、GloVe)或预训练语言模型(如BERT)来捕获语义信息。
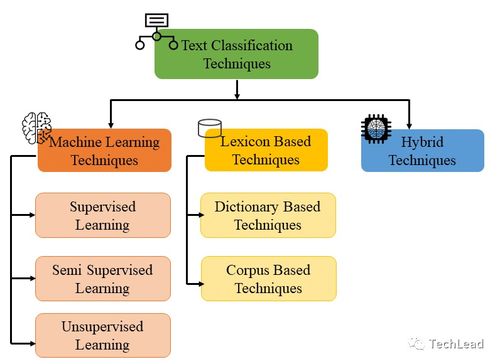
- 模型训练:使用标注数据训练分类器。常见的分类算法包括朴素贝叶斯、支持向量机和决策树;在深度学习中,常使用卷积神经网络、循环神经网络或Transformer架构。
- 分类与评估:将新文本输入训练好的模型,输出类别概率,并通过准确率、精确率、召回率等指标评估性能。
二、关键技术
- 特征表示技术:传统方法依赖手工特征,但深度学习方法通过端到端学习自动提取特征,显著提升了分类效果。例如,BERT等预训练模型能够捕获上下文依赖,适用于复杂文本场景。
- 模型优化技术:包括超参数调优、正则化和集成学习,以提高泛化能力。在基础软件开发中,结合迁移学习可快速适应新领域。
- 处理不平衡数据技术:使用过采样(如SMOTE)或代价敏感学习,解决类别分布不均的问题。
- 可解释性技术:通过注意力机制或LIME等方法,增强模型透明度,便于在软件应用中调试和信任。
三、人工智能基础软件开发中的应用
在基础软件开发中,文本分类被集成到智能客服、垃圾邮件过滤和情感分析等模块。开发过程需注重数据管理、模型部署和实时推理优化。例如,使用TensorFlow或PyTorch框架构建模型,并通过Docker容器化部署,确保可扩展性和效率。
文本分类结合人工智能原理和先进技术,已成为智能系统的基石。未来,随着大模型和自动化机器学习的发展,其准确性和效率将进一步提升,推动基础软件向更智能的方向演进。